Airflow는 파이썬으로 작성된 데이터 파이프라인 (ETL) 프레임워크

- Airbnb에서 시작한 아파치 오픈소스 프로젝트
- 가장 많이 사용되는 데이터 파이프라인 관리/작성 프레임웍
- 데이터 파이프라인 스케줄링 지원
- 정해진 시간에 ETL 실행 혹은 한 ETL의 실행이 끝나면 다음 ETL 실행
- 웹 UI를 제공하기도 함
- 데이터 파이프라인(ETL)을 쉽게 만들 수 있도록 해줌
- 다양한 데이터 소스와 데이터 웨어하우스를 쉽게 통합해주는 모듈 제공 https://airflow.apache.org/docs/
- 데이터 파이프라인 관리 관련 다양한 기능을 제공해줌: 특히 Backfill
- Airflow에서는 데이터 파이프라인을 DAG(Directed Acyclic Graph)라고 부름
- 하나의 DAG는 하나 이상의 태스크로 구성됨
- Airflow 버전 선택 방법: 큰 회사에서 사용하는 버전이 무엇인지 확인. https://cloud.google.com/composer/docs/concepts/versioning/composer-versions
오픈소스 최신버전은 오류가 많기때문에 쓰는게 좋은게아니다
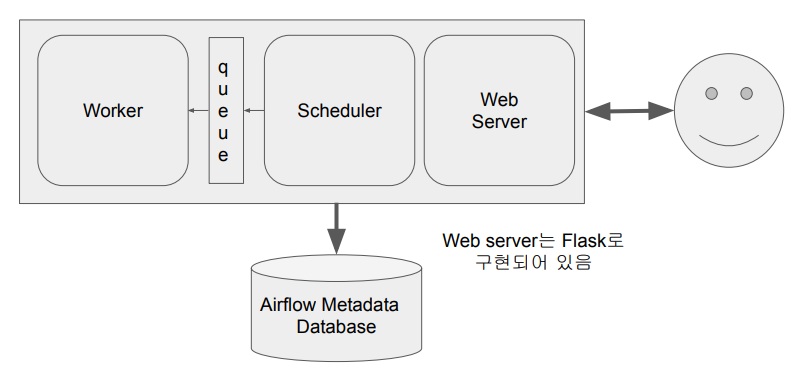
구성
1. Web Server
2. Scheduler: 정해진시간마다 특정 대그를 실행해준다
3. Worker : 실행해주는곳
4. Database (Sqlite가 기본으로 설치됨) : 결과 등 정보들이 기록되는 곳
5. Queue Worker가 다수의 서버로 구성되어있을때
서버가 한대일때 구조
Airflow 스케일링 방법
- 스케일 업 (더 좋은 사양의 서버 사용) : 최대한 이 방법을 사용하는 것이 좋다. 서버가 많으면 오류 날 확률 up
- 스케일 아웃 (서버 추가)
스케일 아웃을 해서 서버가 여러대일때 구조

장점
- 데이터 파이프라인을 세밀하게 제어 가능
- 다양한 데이터 소스와 데이터 웨어하우스를 지원
- 백필(Backfill)이 쉬움
단점
- 배우기가 쉽지 않음, 백필 이해가 어려움
- 상대적으로 개발환경을 구성하기가 쉽지 않음
- 다수서버는 운영이 어려움 운영이 쉽지 않음. 클라우드 버전 사용이 선호됨
- 클라우드 버전
■ GCP provides “Cloud Composer”
■ AWS provides “Managed Workflows for Apache Airflow”
■ Azure provides “Azure Data Factory Managed Airflow”
DAG
- Directed Acyclic Graph의 줄임말
- Airflow에서 ETL을 부르는 명칭
- DAG는 태스크로 구성됨
- 태스크란? - Airflow의 오퍼레이터(Operator)로 만들어짐
- Airflow에서 이미 다양한 종류의 오퍼레이터를 제공함
- 경우에 맞게 사용 오퍼레이터를 결정하거나 필요하다면 직접 개발
- e.g., Redshift writing, Postgres query, S3 Read/Write, Hive query, Spark job, shell script
구성 예제

- 3개의 Task로 구성된 DAG
- 먼저 t1이 실행되고 t2, t3의 순으로 일렬로 실행

- 3개의 Task로 구성된 DAG.
- 먼저 t1이 실행되고 여기서 t2와 t3로 분기
모든 Task에 필요한 기본 정보
default_args = {
'owner': 'whdgus',
'start_date': datetime(2020, 8, 7, hour=0, minute=00),
'end_date': datetime(2020, 8, 31, hour=23, minute=00),
'email': ['whdgus@naver.com'],
'retries': 1,
'retry_delay': timedelta(minutes=3),
}DAG에 필요한 정보
from airflow import DAG
test_dag = DAG(
"HelloWorld", # DAG 이름
schedule="0 9 * * *", # 크론탭문법을 따름 매일 9시 0분에 실행됨, 영국런던기준
tags=['test'] # DAG 태그
default_args=default_args
)
※ 크론탭 문법
* * * * * : 분 시 일 월 요일(0:일요일)
0 * * * * : 0분 매시간마다
0 12 * * * : 12시 0분 하루에 한번
30 6 * * 0 : 매주 일요일 6시 30분
Operators Creation Example
from airflow.operators.bash import BashOperator
#태스크를 3개 만든다
t1 = BashOperator(
task_id='print_date',
bash_command='date',
dag=test_dag)
t2 = BashOperator(
task_id='sleep',
bash_command='sleep 5',
retries=3,
dag=test_dag)
t3 = BashOperator(
task_id='ls',
bash_command='ls /tmp',
dag=test_dag)
t1>>t2
t1>>t3
#t1>>[t2,t3]from airflow.operators.bash_operator import BashOperator
from airflow.operators.dummy_operator import DummyOperator
start = DummyOperator(dag=dag, task_id="start", *args, **kwargs)
t1 = BashOperator(
task_id='ls1',
bash_command='ls /tmp/downloaded',
retries=3,
dag=dag)
t2 = BashOperator(
task_id='ls2',
bash_command='ls /tmp/downloaded',
dag=dag)
end = DummyOperator(dag=dag, task_id='end', *args, **kwargs)
start >> t1 >> end
start >> t2 >> end데이터 파이프라인을 만들 때 고려할 점
데이터 파이프라인은 많은 이유로 실패한다
■ 버그 :)
■ 데이터 소스상의 이슈: 페이스북 api 동작안하면 해결방법이 없음
■ 데이터 파이프라인들간의 의존도에 이해도 부족
○ 데이터 파이프라인의 수가 늘어나면 유지보수 비용이 기하급수적으로 늘어남
■ 데이터 소스간의 의존도가 생기면서 이는 더 복잡해짐. 만일 마케팅 채널 정보가 업데이트가 안된다면 마케팅 관련 다른 모든 정보들이 갱신되지 않음 -> 이름 함부로 바꾸지 않기
■ More tables needs to be managed (source of truth, search cost, …)
추천방법
가능하면 데이터가 작을 경우 매번 통채로 복사해서 테이블을 만들기 (Full Refresh)
Incremental update만이 가능하다면, 대상 데이터소스가 갖춰야할 몇 가지 조건이 있음
- 데이터 소스가 프로덕션 데이터베이스 테이블이라면 다음 필드가 필요:
■ created (데이터 업데이트 관점에서 필요하지는 않음)
■ modified
■ deleted
○ 데이터 소스가 API라면 특정 날짜를 기준으로 새로 생성되거나 업데이트된 레코드들을 읽어올 수 있어야함
멱등성(Idempotency)을 보장하는 것이 중요
- 동일한 입력 데이터로 데이터 파이프라인을 다수 실행해도 최종 테이블의 내용이 달라지지 말아야한다. 예를 들면 중복 데이터가 있으면 안되고 데이터가 부족하면 안된다
실패한 데이터 파이프라인을 재실행이 쉬어야함
- 과거 데이터를 다시 채우는 과정(Backfill)이 쉬어야 함
- Airflow는 이 부분(특히 backfill)에 강점을 갖고 있음
데이터 파이프라인의 입력과 출력을 명확히 하고 문서화
- 데이터 디스커버리 문제!
- 파이프라인이 많아질수록 뭔지,누가만든건지 헷갈림, 최소 주석으로라도 누가 요청했는지 작성
- 주기적으로 쓸모없는 데이터들을 삭제
데이터 파이프라인 사고시 마다 사고 리포트(post-mortem) 쓰기
- 비슷한 사고의 발생을 막기 위함
- 중요 데이터 파이프라인의 입력과 출력을 체크하기
- 아주 간단하게 입력 레코드의 수와 출력 레코드의 수가 몇개인지 체크하는 것부터 시작
- 써머리 테이블을 만들어내고 Primary key가 존재한다면 Primary key uniqueness가 보장되는지 체크하는 것이 필요함
- 중복 레코드 체크
Full Refresh vs. Incremental Update
Full Refresh
- 매번 소스의 내용을 다 읽어오는 방식
- 효율성이 떨어질 수 있지만 간단하고 소스 데이터에 문제가 생겨도 다시 다 읽어오기에 유지보수가 쉬움
- 데이터가 커지면 사용불가
Incremental Update
- 효율성이 좋지만 복잡해지고 유지보수가 힘들어짐
- 보통 daily나 hourly로 동작해서 그 전 시간 혹은 그 전 날 데이터를 읽어오는 형태로 동작
'데이터 엔지니어링 > 실리콘밸리에서 날아온 데이터 엔지니어링 스타터 키트 with Python' 카테고리의 다른 글
| [2주차] SQL JOIN & 고급문법 (0) | 2023.06.12 |
|---|---|
| [2주차] SQL 장단점 & 기본 문법 (0) | 2023.06.12 |
| [1주차]AWS가 제공하는 데이터 웨어하우스 Redshift에 대해 알아보자 (0) | 2023.06.07 |
| [1주차] 데이터 엔지니어링, 데이터 웨어하우스란? (0) | 2023.06.07 |
| [1주차] 데이터 팀의 비전과 가치를 만들어내는 방법 (0) | 2023.06.06 |



댓글